







정식으로 팔랑크스 클럽(동아리)의 절차에 따라, 시즌을 등록한 크루 외에는 제공, 안내되지 않습니다.
허가되지 않는 배포/재가공/캡처 등이 이루어질 시 관련 법령에 따라
손해배상 및 저작권 침해 소송을 제기할 수 있으니, 각별히 유의 바랍니다.
(본 사항은 법령 자문에 따라 '모두' 가 볼 수 있는 명시적 근거를 설립하는 과정임을 재명기합니다.)
STEP 01 . 나의 기획은 ‘ 누구 ’ 에게 필요한가요 ?

제타(Zeta), AI 챗봇과 함께 펼치는 상상의 나래
제타는 유저가 자신이 원하는 캐릭터와 함께 대화할 수 있는 ai 챗봇 서비스입니다.
유저는 이미 만들어져 있는 캐릭터 중 원하는 캐릭터와 대화하거나, 자신이 직접 캐릭터를 생성하고 대화할 수 있습니다.
제타는 같은 회사(스캐터랩)에서 운영되던 AI 챗봇 서비스 너티(Nutty)를 흡수하여 2024년 4월에 출시되었습니다.
그래서 너티에 등장했던 이루다, 강다온 같은 캐릭터들은 제타에서도 만나볼 수 있습니다.
STEP 02 . 나의 기획은 ‘ 무엇 ’ 을 해결하나요 ?

제타는 출시 2개월 만에 이용자 16만 명을 돌파하고, 이용자들의 하루 평균 사용 시간은 약 134분을 달성할만큼 엄청난 인기를 끌었습니다(AI 타임스). 하지만 2024년 7월 6일 기준 구글 플레이스토어의 평균 별점은 2.8로 상당히 낮은 편입니다.
제타는 많은 사용자들이 이용함에도 불구하고 낮은 별점을 받은 이유를 분석하기 위해 2024년 4월 이후의 리뷰를 스크래핑하고, 토픽 모델링 기법 중 하나인 NMF 기법을 사용하여 위와 같이 리뷰의 유형을 세분화 해보았습니다.
참고 1) NMF 분석에 사용한 코드 (더보기 클릭)
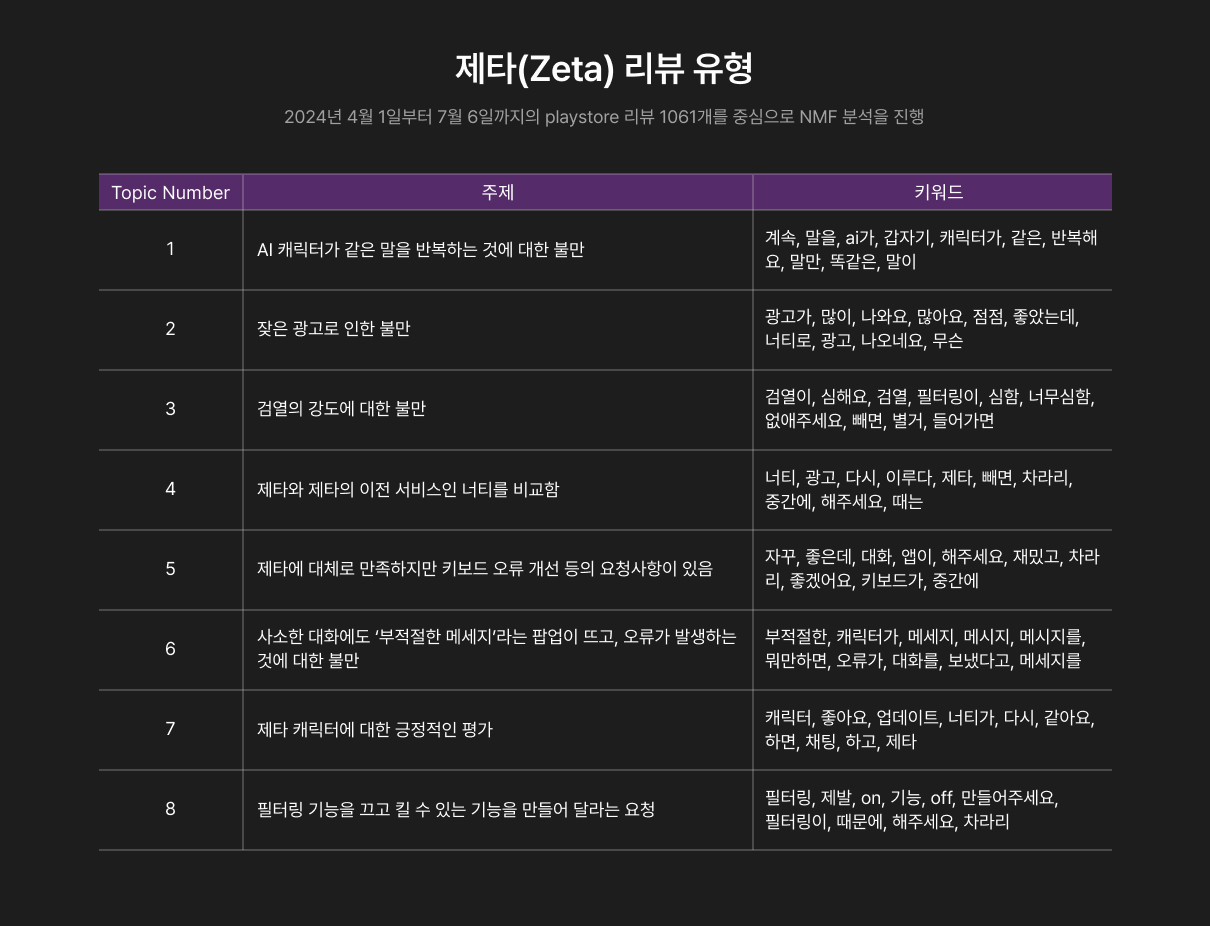
세분화 결과, 리뷰는 위와 같이 8개의 유형으로 분류할 수 있었습니다. 여기서 가장 중요하게 보아야 할 리뷰 유형이 무엇인지 파악하기 위하여 어떤 키워드가 가장 빈번하게 나오는지 알아보았습니다.

2024년 4월 1일부터 제타 플레이스토어 리뷰에서 가장 많이 나온 키워드는 아래와 같습니다.
1위. 부적절한 (133회)
2위. 광고가 (71회)
3위. 필터링 (54회)
4위. 광고 (47회)
5위. 검열 (37회)
6위. 검열이 (36회)
7위. 광고도 (30회)
7위. 오류가 (30회)
8위. 원하는 (25회)
9위. 좋은 (24회)
참고 2) 워드클라우드를 제작하는 데에 사용한 코드 (더보기 클릭)
참고 3) 가장 많이 등장한 키워드 TOP 10을 구하는 데에 사용한 코드 (더보기 클릭)

앞에서 나온 부정적 키워드를 유사한 성격끼리 분류하면 제타의 주된 문제점은 크게 광고, 필터링(검열), 오류 3가지로 나누어짐을 파악할 수 있었습니다. 그리고 그 중에는 검열(필터링)에 대한 리뷰가 가장 많음을 파악할 수 있습니다.

제타는 인공지능이 혐오발언 등 반사회적인 대화를 학습하는 것을 방지하기 위해 검열 시스템을 운영하고 있습니다. 그래서 사용자가 부적절하다고 판단되는 채팅을 친다면, 제타는 대화 진행이 더 이루어지지 않도록 차단합니다. 이 과정에서 사용자들은 원활한 대화 경험을 방해받아 제타에 대해 부정적으로 생각하게 됩니다.

따라서 이번 기획에서 다룰 문제 상황은 “제타의 사용자들이 검열로 인해 불만족스러운 서비스 경험을 한다”로 정의합니다. 이에 대한 분석 근거는 Topic 3, Topic 6, Topic 8의 사용자 리뷰들입니다.
STEP 03 . 그 문제는 ‘ 왜 ’ 발생하였나요 ?
그렇다면 제타 사용자들은 대화 검열의 어떤 점에서 불편을 느낄까요? playstore 리뷰 중 대화검열이 불편한 이유를 자세히 묘사한 리뷰 83개를 바탕으로 분석해 보았습니다.
1. 검열로 인해 대화가 중단되면, 몰입에 방해됨

제타에서 사용자가 부적절한 대화를 입력하고, 그로 인해 캐릭터가 부적절한 말을 하게되면 사용자가 입력한 말과 캐릭터의 답변이 삭제됩니다. 이는 캐릭터와 실제로 대화하고 있다는 분위기를 파괴해 몰입을 저해합니다. 이로 인해 많은 사용자들은 검열에 대한 불만을 가지게 되었습니다.
2. 검열 기준이 불규칙해 어떤 기준으로 채팅해야할 지 혼란스러움

제타의 검열 시스템은 원래 욕설, 성적인 발언, 혐오발언 등의 부적절한 대화 내용을 검열하기 위한 것이었습니다. 하지만 수위가 높지 않은 대화, 일상적인 대화를 입력했음에도 검열되었다는 사용자들이 존재했습니다. 일상적인 대화를 진행했음에도 불구하고 검열되자 사용자들은 어떤 기준에 맞춰 대화를 이어나가야할지 혼란을 겪게 되었습니다.
3. 검열 때문에 대화가 끊긴 후, 어떤 대화를 해야할 지 모르겠음

검열때문에 대화가 끊기자 사용자들은 원래 하려던 말을 하지 못해 어떤 말을 이어나가야할 지 고민에 빠집니다. 이러한 경험은 사용자들이 캐릭터와 지속적으로 대화하는 데에 방해요소가 될 것입니다.

따라서 지금까지의 문제 원인을 정리하자면 다음과 같습니다.
원인 1 사용자들은 검열로 인해 대화가 중단되어 대화에 몰입하지 못한다.
원인 2 사용자들은 검열 기준을 제대로 이해하지 못해 혼란을 겪는다.
원인 3 사용자들은 검열을 겪은 뒤 어떤 말을 해야할 지 고민에 빠진다.
STEP 04 . 그 문제는 ‘ 어떻게 ’ 해결되나요 ?

앞선 단계에서 제타 사용자들이 검열을 싫어하는 이유를 3가지로 정리해보았습니다.
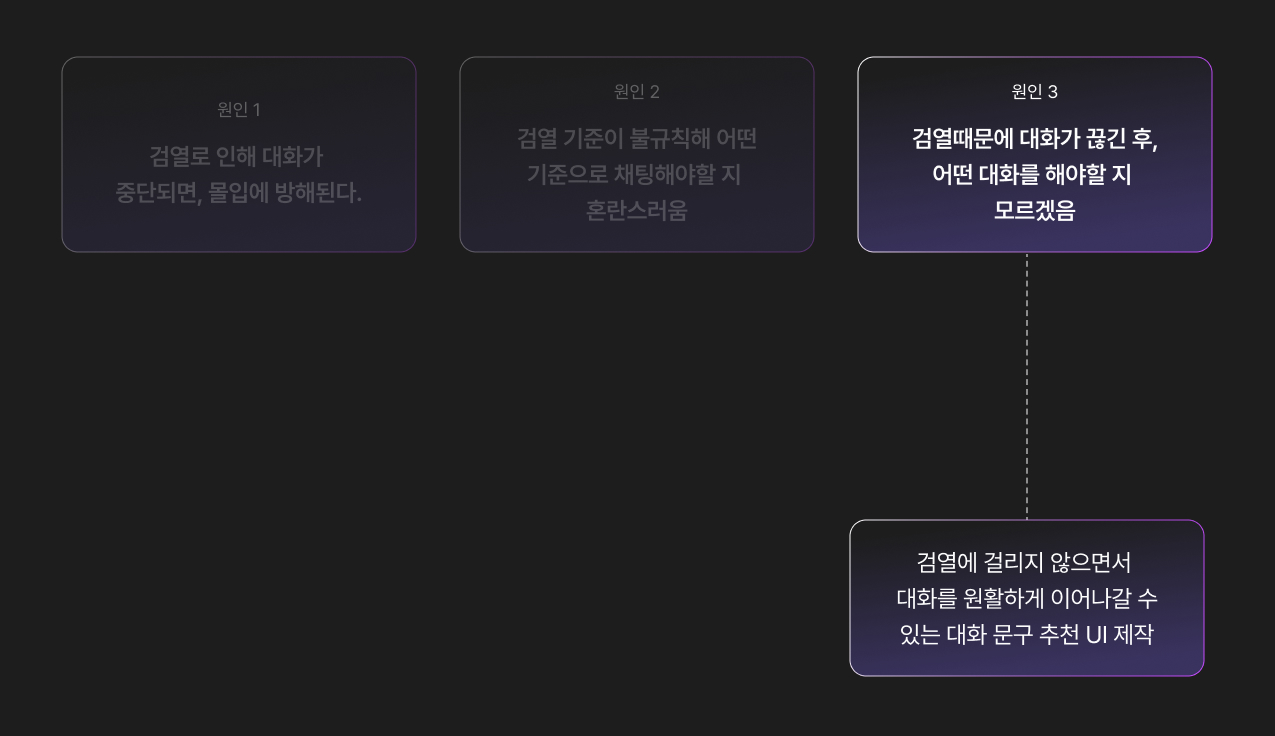
이번 기획에서는 3가지의 원인을 모두 해결하는 것이 아니고, "검열때문에 대화가 끊긴 후 어떤 대화를 해야할 지 고민에 빠지는 상황"을 해결하고자 합니다. 캐릭터와의 자연스러운 대화는 사용자들이 제타를 이용하는 핵심 목적이고, 이것을 유연하게 만드는 것이 제타의 사용자 경험을 증진할 수 있는 길이기 때문입니다. 따라서 이를 이루기 위해 검열에 걸리지 않으면서 대화를 원활하게 이어나갈 수 있는 대화문구 추천 UI를 제작하고자 합니다.
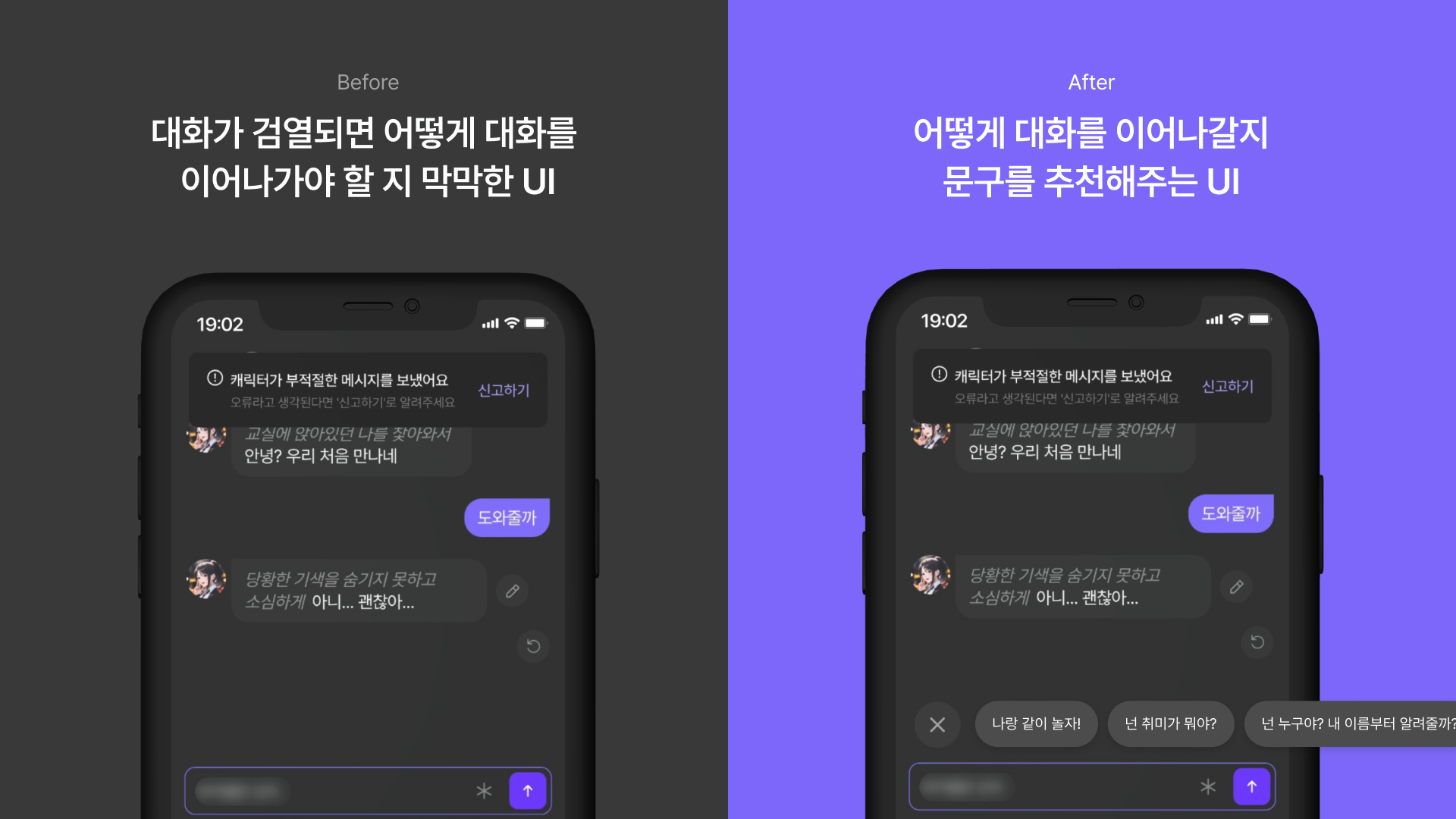
이전 UI는 사용자들의 대화를 삭제하면서 대화를 방해할 뿐, 대화를 어떻게 해야할 지 돕지 않았습니다. 따라서 사용자들이 어떻게 대화를 이어나가야할 지 모를 때 적절한 문구를 추천해주는 UI를 제안합니다.
해당 UI가 사용자들의 대화 경험을 향상시키려면 아래와 같은 전략들이 추진되어야할 것입니다.
1. 추천 문구는 제타의 검열에 걸리면 안된다.
추천 문구가 제타의 검열에 걸린다면 사용자는 해당 기능을 사용하는 데에 있어 크게 불편함을 느낄 것입니다. 따라서 추천 문구는 검열에 걸리지 않고 AI 캐릭터와의 건전한 대화를 이끌어야합니다.
2. 추천 문구는 사용자의 흥미를 끌어야한다.
추천 문구는 사용자가 보았을 때 재미있는 대화가 이어질 것 이라는 예상이 들도록 만들어져야합니다. 흥미를 끌 수 있는 문구의 예시로는 사용자가 원래 입력하려고 했던 내용과 유사한 문구, 사용자가 입력하려고 했던 내용과 전혀 다르지만 참신한 대화를 이끌어 갈 수 있을 것 같은 문구 등이 있습니다.
STEP 05 . 이 문제가 해결되면, 이후 ‘ 어떤 효과 ’ 가 창출되나요 ?
1. 사용자의 제타 이용 시간 증가

대화 문구 추천 시스템은 사용자의 대화가 지속적으로 이어질 수 있도록 도울 것입니다. 따라서 제타의 평균 이용시간은 증가할 것입니다.
2. 신규 사용자 진입 가능성 증가
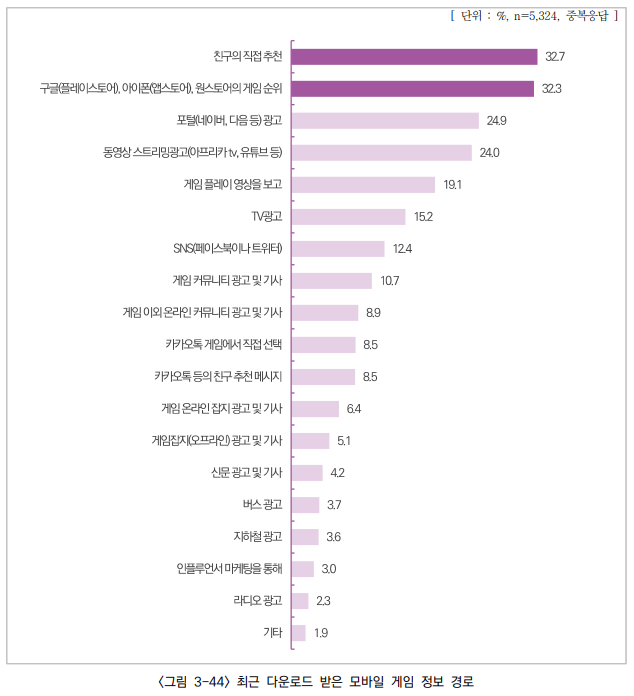
2023 게임이용자 실태조사 보고서에 따르면, 친구의 직접 추천으로 인해 게임을 다운로드 받는 비율이 32.7%입니다. 만약 제타의 문구 추천 기능이 사용자들에게 좋은 경험을 제공한다면, 사용자는 본인의 친구나 지인에게 제타를 추천하여 신규 사용자가 유입될 가능성이 높아질 것입니다.
STEP 06 . 그래서 ! 기획의 목표 는 이렇습니다.
따라서 저의 기획 목표는 아래와 같습니다!

기획자로서, 해당 기획은 제타의 사용자 경험을 긍정적으로 향상시키는 전략이라고 판단한다.
Zeta is watching you 😶_끝

'💻IT팀 > 🧩[일반] 파트🧩' 카테고리의 다른 글
| 시작부터 어려워.....그랑 콜레오스..... (3) | 2024.07.13 |
|---|---|
| ⭐내 기획안이 더욱 잘보이게⭐ "가시화" (0) | 2024.07.08 |
| 컬리, 컬리? 팔로미! (6) | 2024.07.06 |
| 📄 <(🧱)< 🎨 [🖼️] (해석: 글을 압도할 수 있는 이미지 [이미지화]) (0) | 2024.07.06 |
| 돌아오라 쿠키들이여 (3) | 2024.07.06 |
