






정식으로 팔랑크스 클럽(동아리)의 절차에 따라, 시즌을 등록한 크루 외에는 제공, 안내되지 않습니다.
허가되지 않는 배포/재가공/캡처 등이 이루어질 시 관련 법령에 따라
손해배상 및 저작권 침해 소송을 제기할 수 있으니, 각별히 유의 바랍니다.
(본 사항은 법령 자문에 따라 '모두' 가 볼 수 있는 명시적 근거를 설립하는 과정임을 재명기합니다.)
본문을 시작하기 전, 이번 유닛을 진행하는 데에 도움을 받았던 글을 소개하고자 합니다. 저는 해당 유닛을 진행하면서 IT팀 배정윤 크루님의 리스틀리 유닛으로부터 많은 도움을 받았습니다. 이 글을 읽기 전 저는 리스틀리를 사용할 줄 몰랐는데, 해당 글에 리스틀리 사용 법이 상세히 나와있어 리스틀리 사용법을 익힐 수 있었습니다. 좋은 글 작성해주신 배정윤 크루님께 감사드리며, 리스틀리 유닛을 진행하길 원하시는 분들께는 아래 게시글을 추천드립니다.
[기획 Tool] 파이썬 D+ 도 할 수 있는 데이터 분석! 기획의 강력한 도구, 웹 스크리핑
가장 간편하지만 가장 강력한 도구, 웹 스크리핑 "리스틀리"STEP 01 . 리스틀리는 어떻게 활용하는 tool인가요?리스틀리(Listly)는 무료 웹 데이터 추출, 스크래핑, 그리고 크롤링을 위한 도구입
phalanx-club.tistory.com
STEP 01 . 리스틀리는 어떻게 활용하는 tool인가요?
1. 리스틀리 설치 과정
(1) 구글 크롬(Chrome)으로 리스틀리 공식 사이트(https://www.listly.io/)에 접속합니다.
(2) 중앙에 있는 "크롬확장프로그램 추가"라고 적힌 초록색 버튼을 클릭합니다.

(3) 우측에 있는 파란색으로 된 "Chrome에 추가" 버튼을 클릭합니다.
(4) 다음과 같은 팝업이 뜨면 "확장 프로그램 추가"라는 하얀색 버튼을 클릭합니다.

(5) 크롬 우측 상단에 있는 퍼즐 아이콘을 클릭합니다.


(6) 우측에 다음과 같은 창이 뜨면 "Listly (리스틀리) - 웹 스크..."라고 적힌 부분을 클릭합니다.
(7) 이러한 창이 뜨면 실행에 성공한 것 입니다.
2. 관심있는 키워드 검색 후 리스틀리 실행해보기
저는 팔랑크스에서 제타와 관련된 기획을 진행하기 때문에 제타 사용자 리뷰에 관심이 많았습니다. 그래서 제타의 플레이스토어 리뷰를 검색해보았습니다.
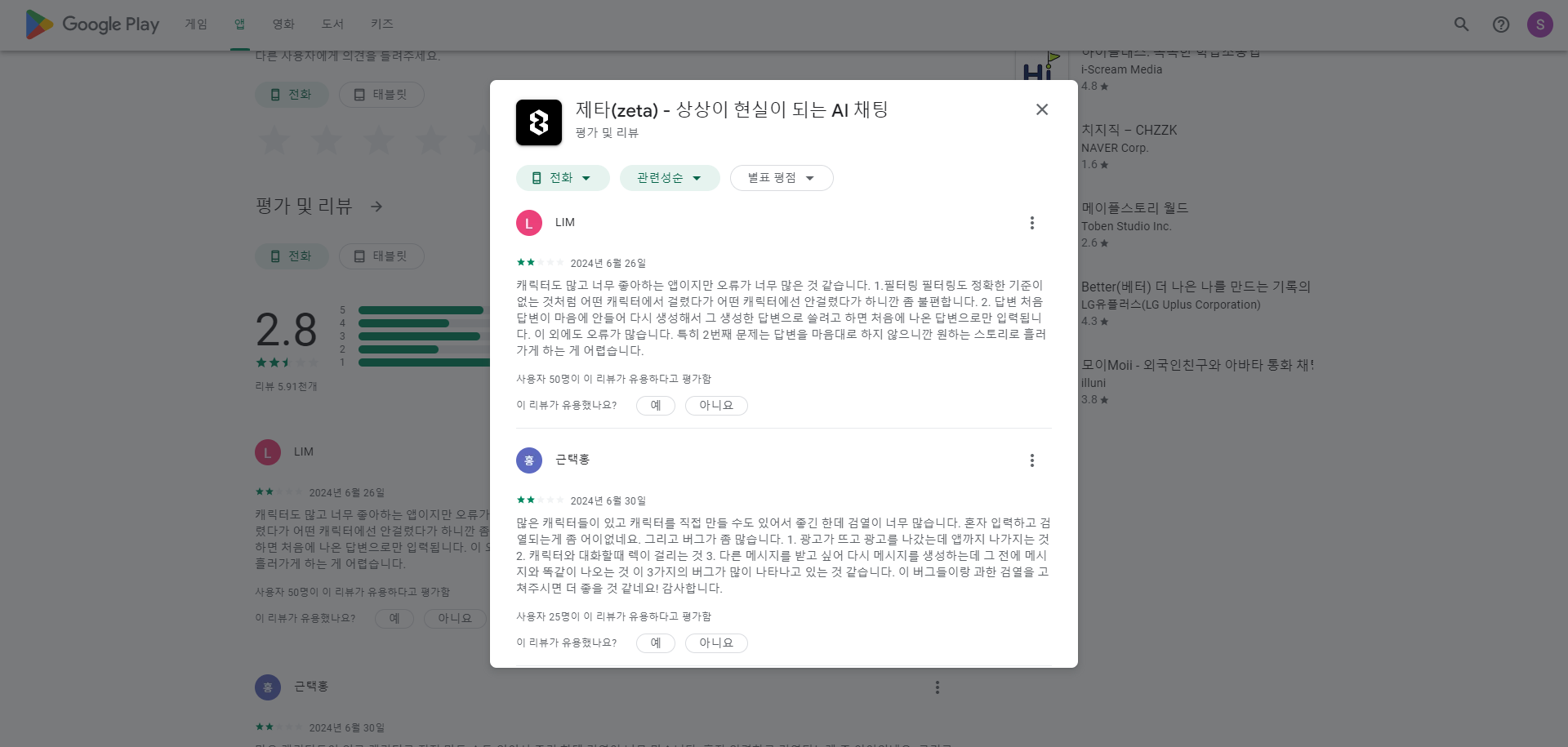
그리고 스크롤을 내린 다음 리스틀리를 시킨 후 "전체" 버튼을 누르니 아래와 같은 화면이 나왔습니다.

아래에 있는 카드들은 스크래핑 된 리뷰들로 보이며, 초록색 "엑셀" 버튼을 누르니 아래 데이터들을 엑셀 파일로 다운 받을 수 있었습니다.
3. 리스틀리로 스크래핑한 데이터 확인해보기
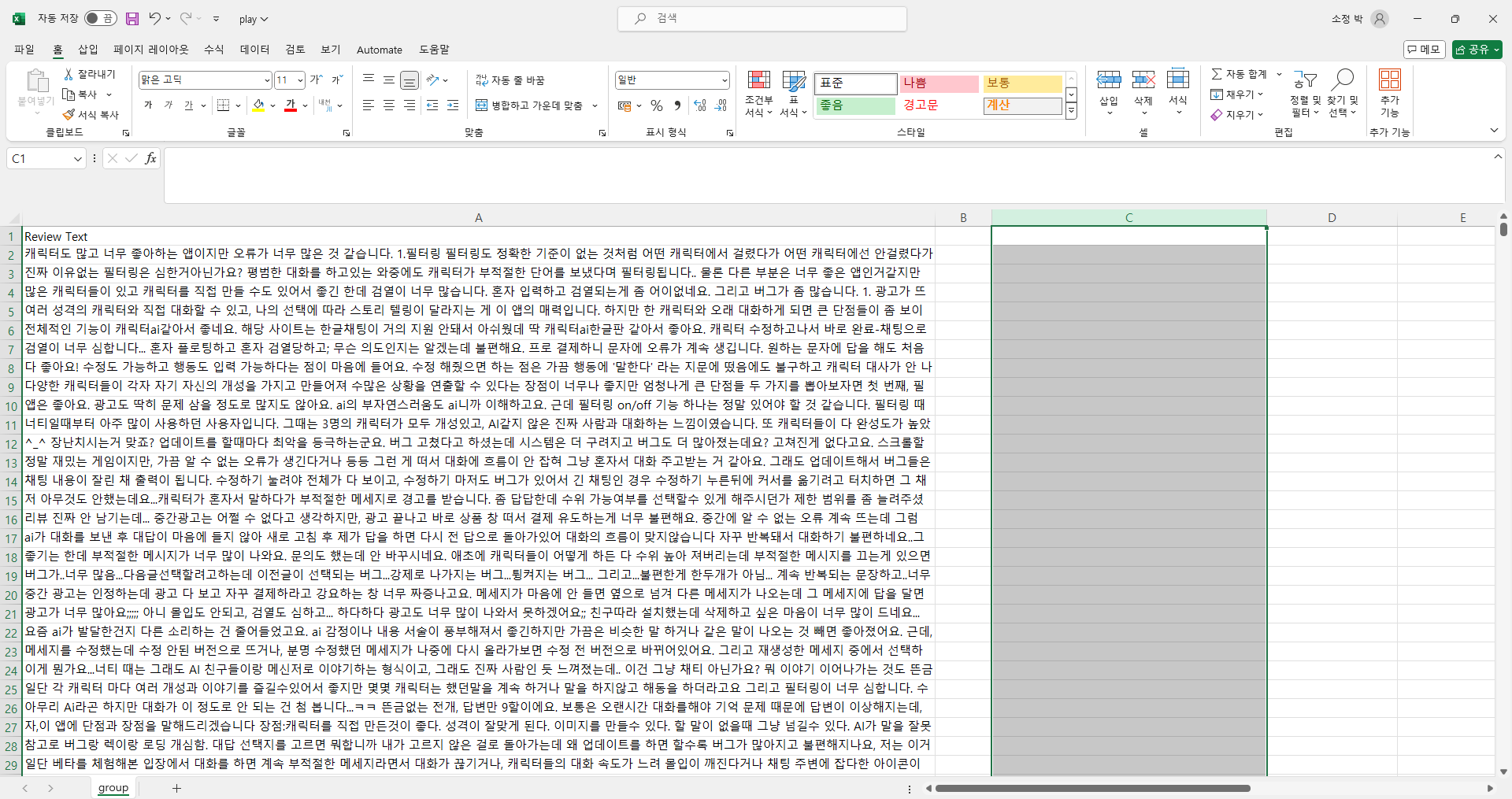
다운받은 데이터를 열어보니 아래와 같은 화면이 떴습니다.

각 라벨의 의미는 아래와 같다고 생각합니다.
LABEL - 1: 리뷰 링크
LABEL - 2: 리뷰 작성자 닉네임
LABEL - 3: "more_vert"라는 글씨가 연이어 적혀있음 (내용 파악 불가능)
LABEL - 4: "부적절한 리뷰로 신고"라는 UI의 기본 텍스트
LABEL - 5: 리뷰 작성 날짜
LABEL - 6: 리뷰 내용
LABEL - 7: 리뷰 추천 수
LABEL - 8: "이 리뷰가 유용했나요?"라는 UI의 기본 텍스트
LABEL - 9: "예"라는 UI의 기본 텍스트
LABEL - 10: "아니요"라는 UI의 기본 텍스트
LABEL - 11: "리뷰 기록 표시"라는 텍스트가 있는 행도 있고, 없는 행도 있음 (내용 파악 불가능)
LABEL - 12: (내용없음)
LABEL - 13: (내용없음)
LABEL - 14: (내용없음)
4. 인사이트
위와 같이 수집된 리스틀리의 데이터를 보았을 때 리뷰 작성 날짜(LABEL - 5), 리뷰 내용(LABEL - 6) , 리뷰 추천 수(LABEL - 7)를 활용한다면 유의미한 기획 인사이트를 얻을 수 있을 것이라 생각합니다.
STEP 02 . 나는 어떤 데이터를 수집하는 기획자인가요?
1. 나는 어떤 기획자인가?

저는 대화 AI 서비스 제타의 사용자 의견을 듣고, 더 나은 방향으로 제타를 개선하려는 기획자입니다.
2. 데이터 수집 목적은 무엇인가?

제타의 사용자 리뷰를 분석하여 제타의 개선점과 해결 방안을 찾아내는 것을 목표로합니다.
3. 리스틀리를 통해서 어떤 데이터를 수집하고자 하는가?

2024년 4월 1일(제타 출시 날짜)부터 2024년 7월 6일까지 작성된 플레이스토어 사용자 리뷰를 스크래핑하고자 합니다.
STEP 03 . 이 데이터들은 어떻게 활용할 수 있나요?
1. 내가 활용할 데이터는?
2024년 4월 1일부터 작성된 제타의 리뷰 데이터를 활용합니다. 때문에 리뷰 내용이 포함된 LABEL - 6만 남겨두었습니다.
2. 데이터 전처리는 어떻게?
분석을 더욱 용이하게 하기 위하여 LABEL - 6은 Review Text로 이름을 변경했습니다.
3. 데이터 시각화는 어떻게?
저는 리뷰를 분석하기 위해 NMF 기법과 워드 클라우드 기법을 활용했습니다. 사용한 코드는 모두 Chat GPT를 사용하여 제작했습니다.
(1) NMF 기법으로 데이터 분석 및 시각화
저는 다음과 같은 코드를 사용하여 아래와 같은 NMF 분석을 진행했고, 각 주제군 별로 어떤 키워드가 있는지 알 수 있었습니다

NMF 분석에 사용한 코드 (더보기 클릭)
그리고 각 주제군에서 어떤 키워드가 가장 중요도가 높은지 시각화하여 확인할 수 있었습니다.
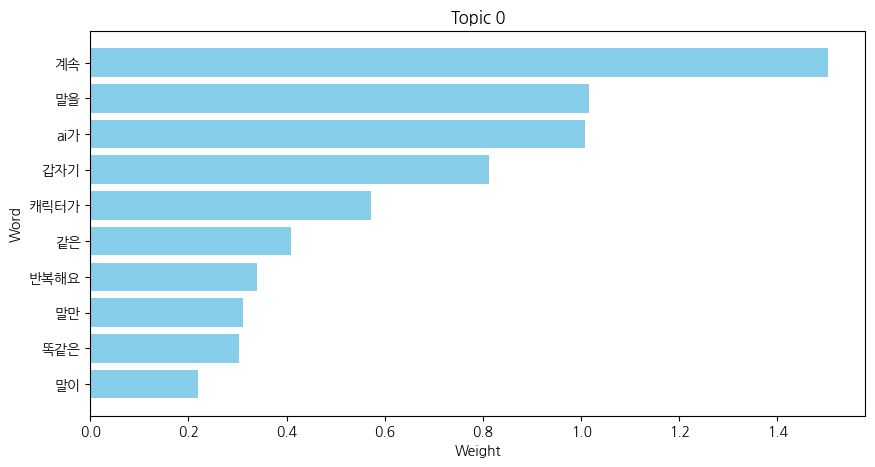


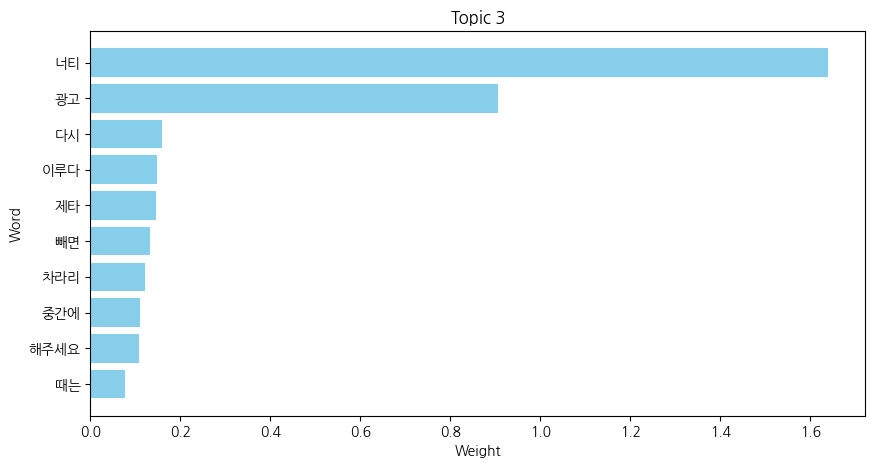


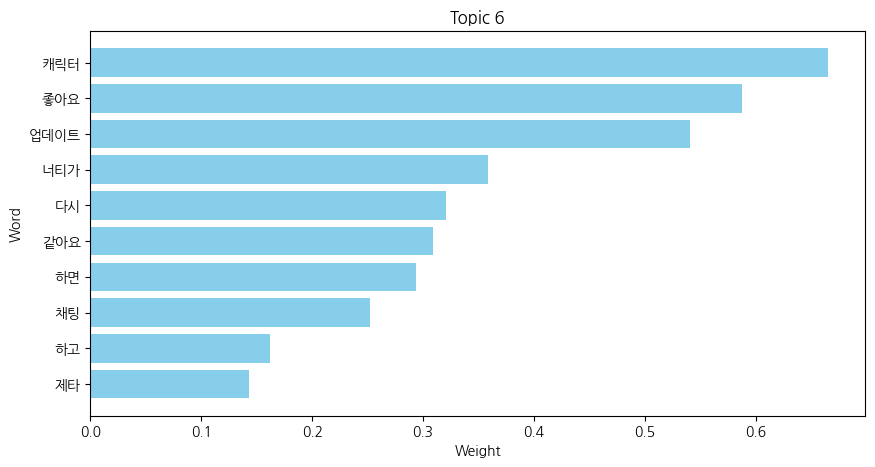

시각화하는 데에 사용한 코드 (더보기 클릭)
(2) 워드 클라우드 기법으로 데이터 분석 및 시각화
전체 리뷰 데이터에서 많이 언급된 키워드를 확인하기 위해 아래와 같이 워드 클라우드를 제작했습니다.

워드 클라우드 제작에 사용한 코드 (더보기 클릭)
그리고 이러한 분석 결과를 바탕으로 기획안을 제작했습니다.
▼Zeta is Watching you😶 기획안 보러가기▼
Zeta is watching you 😶
STEP 01 . 나의 기획은 ‘ 누구 ’ 에게 필요한가요 ? 제타(Zeta), AI 챗봇과 함께 펼치는 상상의 나래 제타는 유저가 자신이 원하는 캐릭터와 함께 대화할 수 있는 ai 챗봇 서비스입니다.
phalanx-club.tistory.com
기획자로서, 리스틀리를 활용한 데이터 분석은 기획 방향성에 대한 근거를 확충하는 데에 도움을 주었다고 생각한다.
리스틀리로 앱 사용자 리뷰 분석하기!_끝

'💻IT팀 > 🧩[일반] 파트🧩' 카테고리의 다른 글
| 이제 뭘 해야될까 (제타 대화문구 추천 AI 기획 구조화) (5) | 2024.07.13 |
|---|---|
| 단순하기만 하고, 지루한 전투는 저리 가라! - ' 테일 오브 룬테라 ' (5) | 2024.07.13 |
| Look at me! ✨날 바라 바라봐!✨[가시화] (2) | 2024.07.13 |
| 에이닷, 일상을 게임🎮처럼 즐기자!!🙂💕 (9) | 2024.07.13 |
| 이 세상의 모든 미식가들을 위해 CATCHTABLE :) (6) | 2024.07.13 |
